
One certainty is that manufacturing processes continue to get better at producing data, primarily due to rapid cost reductions and improvements in data collection, communication, and storage technologies. The challenge, however, is that the ability to exploit this data for meaningful operational benefits is not keeping pace.
There is real potential to use manufacturing data to improve process yields, asset performance optimization, and operational equipment efficiency, and to meet other needs.
The problem is that most current data analysis approaches do not scale well:
- They require large, upfront investments of time and money.
- They rely on the availability of scarce expertise and well-organized data sets.
- They are locked in single-purpose functionality.
 Figure 1. A flood of Figure 1. A flood of process data
Figure 1. A flood of Figure 1. A flood of process data
In many circumstances, the flood of data is actually making things worse by overwhelming in-place human-centric analysis mechanisms, or through distracting "big data" projects that do not produce results. The solution is to find new approaches to using this data that fit within the pragmatic constraints of most industrial and manufacturing settings. Approaches that:
- can be deployed quickly, with very limited upfront investment
- do not require any significant new infrastructure
- are usable by the existing business or operations team
- deliver results quickly
Current approaches and their limitations
Control systems
Control systems are the starting point and center of attention when it comes to process data. Advanced process control approaches, and more specifically multivariate model predictive control approaches, are viable ways to take advantage of expanded process data availability to improve process performance. These techniques require process-specific control system expertise and significant upfront and continuing investments. They are only feasible where they can be applied to specific problems with substantial and predictable payoff.
Ad hoc monitoring capabilities
Outside of the process control systems, a variety of ad hoc approaches are employed to use process data for operational benefit. These approaches center around a process historian or other data store and include:
- dashboards
- rules and thresholds
- formulas and theory-based models
These ad hoc approaches are essential and support many key operational needs, but they are also severely limited in their ability to scale with growing data volumes. Operational dashboards rely on people to interpret them. The more data presented, the more difficult the interpretations. Writing effective rules and thresholds requires expert understanding of the system, and their applicability is often brittle with respect to the system state. Incremental addition of thresholds and alerts can quickly lead to alarm fatigue. Similarly, creating formulas and theory-based models requires domain expertise in addition to controlled, well-understood environments and systems.
Forensic analyses and process optimization
In many situations, retained process data is used primarily in historical analyses. For example, a root-cause analysis is undertaken after an unexpected downtime event or drop in product quality. Periodic process improvement projects examine historical data to benchmark key performance indicators and to identify systemic issues and opportunities for change. This type of data analysis is essential, but it is also expertise and time intensive, and limited in its scope of applicability. Because of the time and human capital required, these types of analyses can only be employed when the benefits are clear, and even then only infrequently. In addition, backward-looking analyses cannot identify arising problems.
Big data projects
Industrial and manufacturing operations are the ultimate producers of big data volumes, far exceeding the e-commerce and search domains that put big data on the map. Machine learning and other technologies associated with big data are clearly applicable to process data analysis, but the "big project" approach used in other application areas has not worked well for industrial and manufacturing operations applications.
A typical project takes several months to complete and requires machine-learning experts, frequent interactions with subject-matter experts, and custom software development. In most cases, periodic follow-up projects are required to keep the models up to date with evolving process and equipment conditions.
Successful big data application examples like speech recognition, fraud detection, or recommendation engines generally provide large, enduring paybacks from vast troves of data that justify the initial investments. Industrial and manufacturing operations applications are extremely numerous, but are much smaller and more context-specific in their applicability. Big data projects have achieved very limited success in industrial and manufacturing operations, and many organizations have learned to distrust the approach altogether.
Pragmatic pattern recognition and classification
If current approaches fail to provide a scalable path, what are the viable alternatives? One option that is gaining traction is using prepackaged machine-learning (ML) technologies that extend existing data storage infrastructure, like process historians. By narrowing the capability focus, an embedded machine-learning capability can eliminate the need for data science expertise or for custom software development.
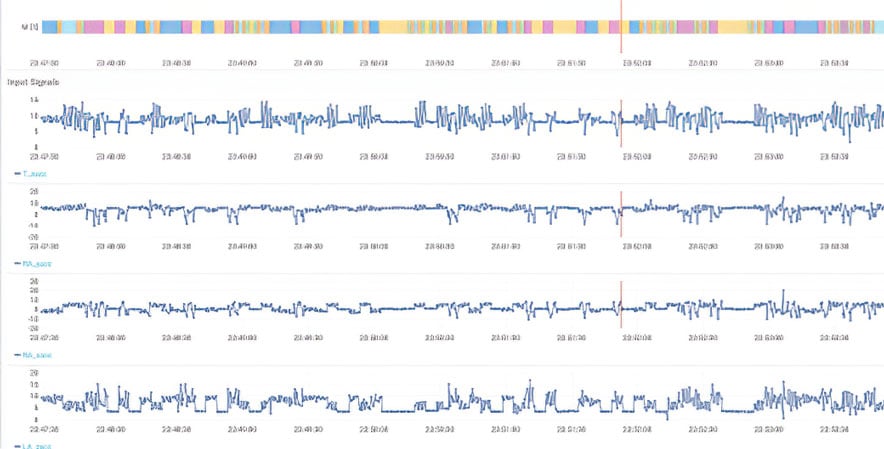 Figure 2. Time series data patterns
Figure 2. Time series data patterns
A specific example of an embedded ML capability is an engine that performs pattern recognition and classification on multivariate time series data, which includes continuously recorded sensor and parametric data, as well as intermittently collected inspection measurements. Process data is largely time series data, and a real-time pattern-recognition engine is a practical way for operations teams to better understand the state of process machinery or the process itself from process data streams.
Pattern recognition and classification could, for example, be used to:
- identify a quality issue with raw materials
- identify process configuration issues
- provide early warning of a maintenance need or impending machine failure
Figure 3 shows the use of a pattern-recognition engine with a process historian. Key elements of this approach include:
- easy deployment and integration to existing data store
- augmentation of the existing data stream (i.e., output feeds back into the data store)
- usable by the existing business or operations team
- No data science requirements, such as feature engineering, algorithm selection, or hyperparameter tuning
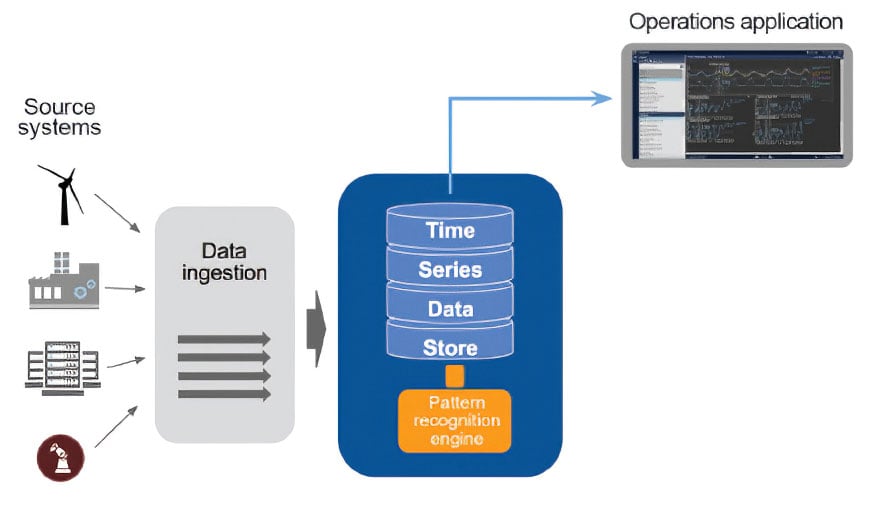 Figure 3. Typical pattern-recognition engine
Figure 3. Typical pattern-recognition engine
Use of a pattern-recognition engine can be simple and straightforward. A user needs to:
- Configure the engine for a particular need
- Select a type of entity of interest (e.g., a machine, a line, a process step or phase)
- Select a set of signals that could contain patterns that reveal the state of each entity
- Validate the model produced by the engine for the desired need
- Manage the execution of the engine
- Tell it when to update models
- Control when it is applied to live (real-time) data
- Provide labels of known conditions against occurrence time, where available
- The engine will find patterns on its own, but it needs the subject-matter experts to give names and contextualization to conditions.
A properly embedded pattern-recognition engine can be used in the same way that historian features, such as calculated fields or attributes, are used to augment raw data streams. For example, the output from the engine can be:
- fed to a control system, making it a form of soft sensor
- used in dashboards, rules, thresholds, and alerts-providing a digested measurement of state
- used in historical data analyses
One advantage of a pattern-recognition-based approach is the flexibility. The models produced are purely data driven, and do not require an understanding of the causal relationships, or a detailed understanding of the signal origin. Large numbers of signals from disparate sources could be speculatively thrown into a pattern-recognition engine to identify conditions. New sensors could be added to attempt to capture phenomena of interest. A simple example is the combination of process execution and quality data with machine trace data from a manufacturing execution system. As long as the data is correlated in time, a pattern-recognition engine can extract useful characterizations of state. This type of data-driven model does not replace the need for theory-based models that offer a more precise characterization of behavior, but they offer a powerful additional tool to the operations team.
How can classification be predictive?
If classification is simply a way to characterize the state of some entity at a particular time, how can it ever be predictive? It is true that an individual classification of a condition state is not a prediction. Some conditions, however, are precursors of other states that are yet to come. The classic example is a downtime condition in a machine. In almost every case, a machine will start exhibiting some changes in behavior before it erodes into a condition that requires downtime. Identifying these early states is how classification can be predictive.
Material processing example
A global leader in mineral production faced a situation like the one described in this article. Investments in instrumentation and data collection were producing large volumes of operational data, but efforts to turn this data into meaningful improvements in operational efficiency were falling short.
The production line experienced frequent, unexpected downtime due to variations in raw material that adversely affected a critical process line machine. These downtime events lasted anywhere from two to 24 hours per occurrence, and they negatively impacted revenue and increased the cost of production.
Data, in the form of motor currents, temperatures, valve settings, and stoichiometric measurements, was collected from the process line, stored in a process historian, and made available to the operations team through dashboards and other means. The thresholds, rules, and engineering-based models in use were, however, unable to reliably identify conditions leading to the downtime events.
To solve this problem, a pattern-recognition engine was installed and integrated with the plant's process historian. Members of the process operations team completed the following tasks in approximately three weeks:
- Configured a data stream for pattern recognition.
- Here there was a single entity corresponding to the material processing line and seven signals corresponding to select motor currents, temperatures, and valve settings along the line.
- The team identified a window of historic data to learn from. This window was chosen to include example periods of known conditions, such as the downtime event.
- Created a model from raw patterns in the seven selected signals from a segment of the provided history window.
- Provided a few examples in the history window of known downtime events and periods of normality.
- Identified possible patterns that could indicate a bad raw material condition leading to the downtime event.
- Created a new model using the provided labels.
- Tested the updated model on other parts of the history window data, and confirmed that the model detected bad raw material conditions up to 12 hours in advance of downtime events.
- Set up notifications in the historian to alert operators of a bad raw material condition.
- Turned on live monitoring of the data stream.
The condition stream produced by the pattern-recognition engine could provide very early warnings of a previously hidden bad raw material condition. This awareness enabled the operations team to take corrective actions and avoid many of the costly downtime events that had plagued them previously.
Process data analysis
Industrial and manufacturing operations data analysis represents a different type of "big data" challenge than those faced in e-commerce, social media, search, or other domains. Process data analysis is a long-tail situation: Data volumes are extremely large, but there are many focused, "small" problems that need to be solved as opposed to a short list of "big" problems. Process data analysis requires a highly scalable approach that puts capabilities in the hands of subject-matter experts and that facilitates quick wins and incremental growth. Pattern recognition proves to be a reliable method of analyzing big data by leveraging existing assets (i.e., tribal knowledge, operational data stores), providing context to events, and uncovering paths for process optimization.
A version of this article also was published at InTech magazine.


